"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Word2Vec
Word2Vec은 자연어 처리에 있어서 단어의 특징을 반영하지 못하는 현실을 극복하여, 단어간의 유사성을 포함하면서 주목 받고 있다.

통계적 자연어 처리에서 언어학의 ‘비슷한 분포를 가진 단어들은 비슷한 의미를 가진다’라는 분산가설(Distributional Hypothesis)과 ‘친구를 보면 그 사람을 안다.’ 또는‘단어의 주변을 보면 그 단어를 안다.’ - 언어학자 J.R Firth의 아이디어를 바탕으로 두고 있다. 맥락으로 단어를 예측하거나 단어로 맥락을 예측하는 predictive method에 속한다.
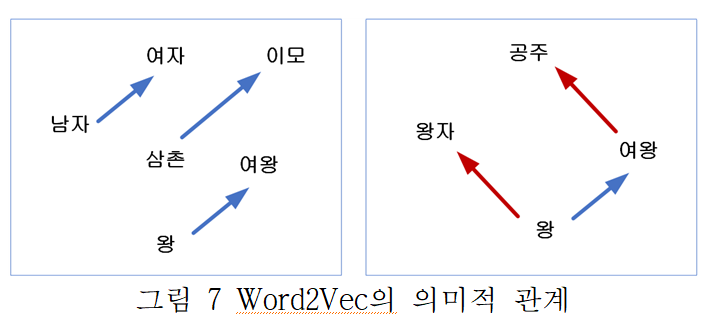
그림7의 word2vec은 Word Embedding을 통해 단어간의 유사성을 포함할 수 있다. 그림처럼 벡터화를 시켰을 때 두 단어의 거리의 유사성을 통해 ‘남자’과 ‘여자’은 ‘왕’과 ‘여왕’을 거리와 유사하기 때문에 의미적인 관계를 갖는다고 볼 수 있다.
Word2Vec의 알고리즘은 두가지 방식이있다. 하나는 맥락으로 단어를 예측하는 CBOW(continuous bag of words) 모델이 있고, 두 번째는 단어로 맥락을 예측하는 skip-gram 모델이다.
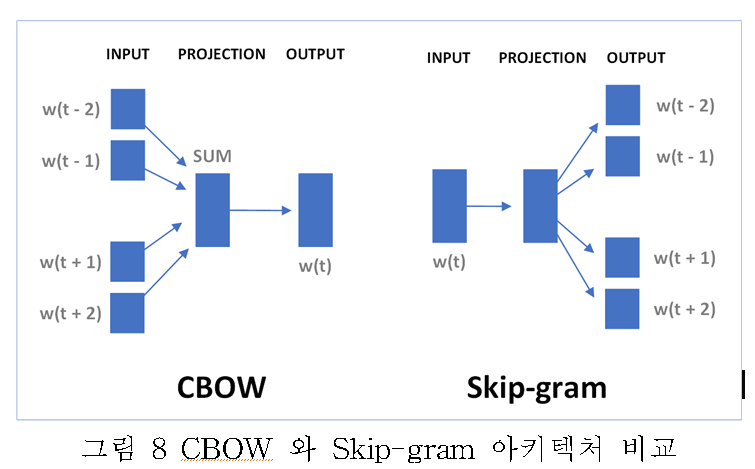
그림8을 통해서, CBOW(Conitnuous Bag-of-Words)는 문장 내에서 주변 단어들을 모델에게 제공하고, 가운데 빈칸에 올 단어가 무엇인지 맞추는 방식으로 워드 임베딩을 학습한다. 즉 K개 만큼의 주변 단어가 주어지면 중심에 올 단어의 조건부 확률을 계산하는 방식이다. Skip-gram은 한 단어를 모델에 제공하면, 모델은 이주변에 어떤 단어들이 놓일지 맞히는 방식으로 학습한다. 즉 주어진 중심 단어 주변의 K개 단어가 어떤 것이 나타날지 조건부 확률을 계산하는 방식이다. Skip-gram 모델이 더 어려운 과제를 수행하며 보다 품질이 더 좋은 경향이 있다.
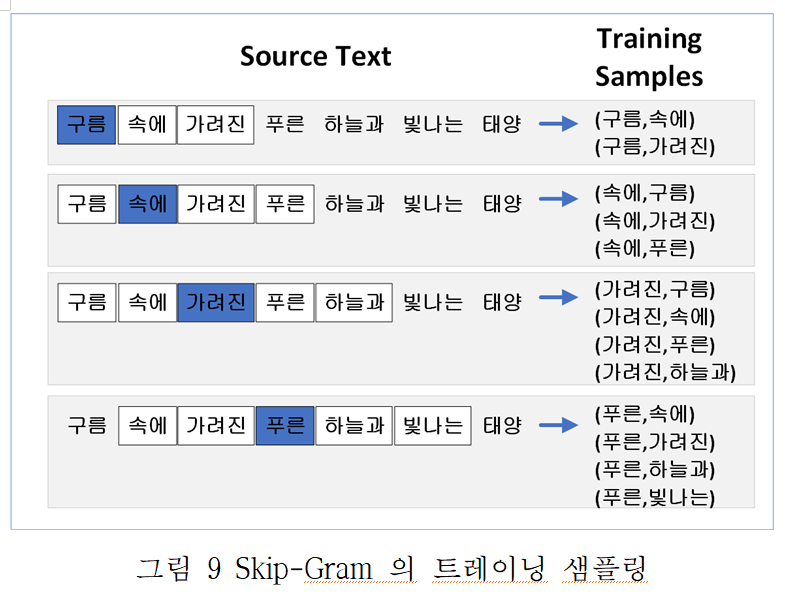
그림 9는 Skip-Gram(중심단어로 주변단어 예측)이 어떻게 말뭉치로부터 트레이닝 샘플을 만드는지 볼수 있다..
‘구름 속에 가려진 푸른 하늘과 빛나는 태양’을 예로 든다. 윈도우(한번에 학습할 단어 개수)크기가 2인 경우 아키텍처가 받는 input과 output은 위의 그림과 같다
처음 등장하는 단어인 구름을 시작으로 양 주변의 2단어를 학습에 이용하게 되며, 슬라이딩 윈도우(다음 단어로 윈도우 이동) 하며 속에, 가려진 각각의 주변 단어를 학습을 진행하며 문장의 모든 단어를 거치면 iteration 1회가 마무리된다.
주변 단어로 중심 단어를 예측하는 CBOW에 비해 Skip-gram의 성능이 좋은 이유는 CBOW의 경우 중심단어(벡터) 단 한번의 업데이트 기회를 갖지만, Skip-gram의 경우 윈도우 크기가 2일 경우 중심단어는 업데이트 기회를 4번이나 확보할 수 있다. 말뭉치 크기가 동일하더라도 학습량이 4 배 차이가 난다.
참고자료
[12]이수경, 이주진, 임성빈, “단어간 유사도 파악 방법” , https://brunch.co.kr/@kakao-it/189, 2018
[13]김병수, “word2vec 관련 이론 정리”, https://shuuki4.wordpress.com/2016/01/27/word2vec-관련-이론-정리/, 2016
[14] “쉽게 씌어진 word2vec”, https://dreamgonfly.github.io/machine/learning,/natural/language/processing/2017/08/16/word2vec_explained.html, 2016
[15]“딥러닝 기반 자연어처리 기법의 최근 연구 동향”, https://ratsgo.github.io/natural%20language%20processing/2017/08/16/deepNLP/#a-단어-임베딩, 2017
'IT' 카테고리의 다른 글
| [IP-PBX] PBX 구성을 위한, OS 및 Asterisk 버전 확인 (0) | 2026.03.12 |
|---|---|
| AI 발전 과정 개념 잡기 (3) | 2025.07.27 |
| [IT] 유전 알고리즘 고찰 및 사례 분석 (0) | 2024.06.08 |
| [IT]챗봇은 어떻게 확률을 이용해서 자연어를 만들어 낼까? (1) | 2024.06.08 |
| 개발자의 글쓰기 방법 (기술 블로거의 글쓰기 방법) (1) | 2024.04.11 |