"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
유전 알고리즘 고찰 및 사례분석 Genetic Algorithm Review and Case Analysis 지현승 요 약 |
| IOT(사물인터넷) 시대의 발달로 인해서 우리는 인공지능을 자주 접하게 되었다. 인공지능이란 어떤 문제가 주어 졌을 때 그 문제에 대해 최선의 선택을 할 수 있는 능력일 것이다. 기기 스스로가 ‘최적의 선택‘을 할 수 있는 인공지능 기술은 ’유전 알고리즘‘에서 찾을 수 있다. 유전 알고리즘은 세대를 거듭함으로써, 최적의 해에 가까워 질 수 있는 알고리즘이다. 즉 최적의 값을 도출할 수 없는 상태에서 가장 적합한 값을 선택 할 수 있게 해 줄 수 있다. 유전 알고리즘에 대한 개념을 알아보고, 유전 알고리즘의 대표적인 문제 외판원 문제를 구현 해 봄으로써 유전 알고리즘에 대한 기본적인 지식과 기술을 습득하고, 다른 유전알고리즘의 활용 사례를 분석하고, 새로운 유전 알고리즘의 문제의식을 통해서 향후 연구 방향을 제안함으로써 유전 알고리즘에 대한 고찰을 마무리 한다. |
1. 서 론
과거의 인공지능은 기술적인 한계, 즉 정보처리 속도가 느리고 메모리도 작아서 인공지능을 구현하기에는 무리가 많았다. 또한 그 실용성에 대한 의문 때문에 주목을 받지 못하였다. 하지만 이제는 IT 기술의 급약적인 발달과 빅데이터 및 분산처리 기술들의 발달로 인공지능은 다시 주목 받게 되었다.
인공지능은 발전단계를 기준으로 삼아 3가지로 분류 할 수 있다. 약인공지능, 강인공지능, 초인공지능이다. 약인공지능은 ‘특정 분야’에서만 쓰이는 것을 의미한다. 사람과 대화할 수 있는 아이폰의 Siri, 구글의 번역기, 네비게이션등 인간 지능으로만 가능하던 작업일부를 컴퓨터로 수행가능하게 만든 것이다. 강인공지능은 인간과 동일한 수준의 지능을 갖추고 약인공지능과 달리 ‘모든 분야’에서 쓰일 수 있다. 초 인공지능은 사람을 뛰어넘는 상태를 의미하며, 인간이 생각하지 못한 것 혹은 새로운 것을 창작할 수 있는 고수준의 인공지능을 이야기 한다. 현재의 인공지능 기술 수준은 약인공지능 단계이다.
IT의 발달은 수많은 정보들이 수집되고 데이터화 되면서 빅데이터 시대를 열어 주었다. 그로인해서 사람은 사람이 다룰수 있는 정보의 양 또한 폭발 적으로 증가 하게 되었다. 사람이 선택하기에 너무나 많은 정보를 고려하게 하는 문제는 너무 복잡하고 어렵다. 우리는 기계 학습 인공지능을 통해서 이런 문제를 해결 할 수 있다.
유전 알고리즘은 아주 복잡한 계산 문제를 풀 수 있다.
계산 문제는 문제의 난이도에 따라 P문제와 NP문제로 나뉜다. P문제는 결정론적 문제로 결과가 유일하게 정의된 연산을 통하여 쉽게 해결할 수 있는 문제이고, NP문제는 비결정론적 문제로 결과값이 상황에 따라 달라질 수 있는 연산을 하여 쉽게 해결할 수 없는 어려운 문제이다.
여러 복잡도가 높은 상황에서 문제 해결의 최선에 근접한 선택을 할 수 있게 해주 유전알고리즘을 통해서 최선의 선택에 대한 실마리를 찾을 수 있을 것이다.
유전 알고리즘은 자연세계의 진화과정을 바탕으로, 다윈의 적자생존 이론을 기본 개념으로 한다. 유전 알고리즘은 문제에 대한 가능한 해들을 정해진 형태의 자료 구조로 표현 하여 나열한 뒤, 세대를 거듭하면서 유전자들을 변형함으로써 정확도가 높고, 좋은 해들을 만들어 낸다. 세대를 거듭하여 좋은 해를 얻는 것, 진화를 통해서 최적의 해를 구할 수 있다.
2장에서 다윈의 적자생존 이론의 개념을 알아보고, 3장에서 유전 알고리즘에 대해 알아보고, 4장은 유전 알고리즘의 대표적인 문제인 외판원 문제(Traveling Salesperson Problem)를 구현하여 시물레이션 함으로써유전알고리즘의 최적의 해 선택과정을 알아보고, 5장에서 유전알고리즘의 활용분야를 끝으로, 유전알고리즘에대한 고찰을 마무리한다.
2. 찰스 로버트 다윈의 ‘적자생존’
다양한 변이를 통해서 다양한 개체가 있다. 이 개체군 중에 환경에 가장 적합한 유전자를 가진 개체가 성공적으로 환경에 적응함으로써 적합한 유전자를 개체만이 살아 남아 자손을 낳아 세대를 거듭하였다. 이것이 바로 ‘적자생존’이다.

환경에 잘 적응 한 개체가 살아남아 자식을 낳는다.
잘 적응한 유전적 특징이 그대로 자식에게 전해지는 것이 아니라, 교배로 두부모의 특징이 섞이기도 한다. 또 전혀 새로운(돌연)변이가 나타나 유전되기도 한다.
환경에 잘 적응한 생물체만이 자손을 남겨, 생존에 유리한 특성을 자손에게 전한다. 여러 세대를 거듭하면서 이런 특성이 점차 쌓이게 되고, 결국에는 선조와 다른 생존에 우수한 특성을 가진 종으로 변화한다. 이것을 적자생존이라 한다.
3. 유전 알고리즘의 정의
유전 알고리즘은 다윈의 적자생존 이론을 기반으로 한 전역 최적화 기법이다. 많은 해 집단 속에서 주어진 문제를 가장 잘 풀어내는 혹은 가장 적합한 해를 선택하는 것을 목표로 하며 이 과정에서 자연계의 진화를 본 딴 여러 연산을 수행한다.

유전 알고리즘은 다음과 같은 몇 가지 특징을 가지고 있다. 각각의 특성을 같은 유전자(gene)들이 모여 하나의 개체(individual)를 이루고, 각각의 개체가 모여 개체군(population)을 이룬다. 유전 알고리즘은 개체군(population)에 기반을 둔 탐색을 수행하며 개체들의 적합도(fitness)를 측정하고, 최적자를 선택(selection)하기 위한 방법과, 기존의 개체군 P(t)를 교차(crossover), 변이(mutation) 대치(replacement)하여 새로운 세대(generation) P(t+1)를 생성하기 위한 유전 연산자들을 지닌다.
일반 적으로 적합도가 높은 개체는 적합도가 더 낮은 개체보다 다음세대에 선택되어 살아남거나 자손을 생산할 확률이 더 높다. 유전 알고리즘은 개체 중에 원하는 수준의 적합도를 갖는 개체가 나타날 때까지 세대교체를 반복함으로써 최적의 해를 찾아낸다.

선택은 높은 적합도를 보이는 상위 염색체를 확률적으로 선택하여 다음 세대의 부모로 사용하고, 교배는 선택된 염색체들을 서로간 교배를 통하여 새로운 구조를 가지는 염색체를 만들어내고, 변이는 교배를 통한 재조합이 끝난 후 일부를 바꾸어주는 과정 자연계 생명체 유전자의 돌연변이이 과정을 거치게 된다.
유전 알고리즘을 설계할 때, 최적해의 정확한 값이나 패턴을 알지 못하기 때문에 목표 적합도를 추정해야한다. 이 과정에서 절대로 나올 수 없는 목표 적합도를 설정하게 되는 경우가 있는데, 이러한 경우에는 알고리즘이 끝나지 않는다. 그래서 매우 복잡한 문제를 풀어야 할때는 목표 적합도 뿐만 아니라 최대 반복 횟수도 같이 설정해주는 것이 일반적이다.
-선택 연산(Selection)
적합도가 높은 개체를 선택해 남기면 다음 세대가 되었을 때 집단 안에서 더 최적 해결책에 가까운 개체가 많아지는 상태를 만들 수 있습니다. 이를 선택이라 한다.
선택의 방법으로 룰렛휠 선택, 토너먼트 선택, 엘리트 선택 등이 있다.

①품질 비례 룰렛휠 선택
각 염색체는 이 룰렛휠 상에 자신의 적합도 만큼의 공간을 배정받는다.여기에 활을 쏘면 각 염색체의 선택 확률은 배정된 공간의 크기에 비례하게 된다.

② 토너먼트 선택
두 개의 염색체를 임의로 선택하여 [0,1) 범위의 난수를 발생 시킨 다음, 이것이 t보다 작으면 두 염색체 중 품질이 좋은 것을 선택하고 그렇지 않으면 품질이 나쁜 것을 선택하는 것이다.

③ 순위 기반 선택
해집단 내의 해들을 품질 순으로 “순위”를 매긴 다음 가장좋은 해부터 적합도를 배정하는 방법으로, 좋은 품질의 해와 나쁜 품질의 해가 지나치게 적합도 차이가 나는 것을 막을수 있다.
④ 공유
해집단의 다양성을 보다 오래 유지하고자 하는 목적에서 고안되었다. 공유는 먼저 품질 비례 선택이나 순위 기반 선택에서 쓰는 적합도 값을 구한뒤, 해당 염색체가 해집단 내의 나머지 염색체들과 유사한(특징을 “공유”하는) 정도가 높을수록 큰 값의 적합도를 갖는다.
-교차연산(Crossover)
부모의 유전자를 재조합해 자식 들을 생성하는 것을 교차라고 한다. 유전자를 변형해 자식을 생성할 때 부모의 유전자를 어떻게 이용하느냐에 따라 1점교차, 다점교차, 균등 교차로 분류 한다.

| 일반적으로 이용하는 교차 | |
| 교차 | 설명 |
| 1점 교차(one point crossover) | 어떤 유전자 위치를 경계로 부모의 유전자를 바꿔 자식을 생성한다. |
| 다점 교차(multi point corssover) | 염색체 위에 1점 교차의 경계를 복수로 설정해 자식을 생성한다. |
| 균등교차(uniform corssover) | 0은 확률 p, 1은 확률 1-p로 설정한 후 부모의 유전자를 바꿔 자식을 생성한다. |
| 평균교차(average crossover) | 부모 유전자의 평균치를 자식의 유전자로 한다. |

| 순열 인코딩에서 이용하는 교차 | |
| 교차 | 설명 |
| 사이클교차 (cyclecrossover) |
①부모1의 특정 유전자 번호와 위치를 자식에게 물려 준다. ②부모1과 같은 위치에 있는 부모2의 유전자 번호를 파악한다. ③ ②에서 파악한 유전자 번호가 있는 부모1의 유전자 번호 위치를 찾은 후 부모1의 유전자 번호와 위치를 자식에게 물려 준다. ④ ①~③을 반복해 ①의유전자번호가 나올때 까지 자식에게 번호를 물려 줍다. ⑤ 자식 유전자에서 가장 왼쪽에 비어 있는 위치와 같은 부모2의 유전자 번호와 위치를 물려준 후 부모2를 기준으로 ②~④를 반복해서 자식 유전자 번호를 채운다. ⑥ 자식 유전자 번호를 모두 채울 때까지 ①~⑤를 반복한다. |
| 부분일치교차 (partiallymatchedcorssover) |
① 경계 2개 사이에 있는 부모1의 특정 유전자 번호들과 위치를자식에게 물려준다. ② ①에서 물려준 유전자 번호와 위치를 제외하고 부모2의 유전자 번호들과 위치를 자식에게 물려 준다. ③ 물려 받은 자식 유전자 번호중 ①과 중복되는 번호가 있다면 해당 번호의 부모1 유전자 번호 위치와 같은 부모2의 유전자 번호로 바꾼다. 이 과정을 반복해 ②에서 물려 받은 번호는 ①의 번호와 중복되지 않게 해 모든 자식 유전자 번호를 채운다. |
| 순서교차 (ordercorssover) |
① 경계 2개사이에 있는 부모1의 특정 유전자 번호들과 위치를 자식에게 물려 준다. ② 부모2의 가장 왼쪽을 기준으로 자식 유전자의 오른쪽 비어있는 부분부터 유전자 번호를 차례로 채운다. 단, ①과 중복되는 번호는 제외하고 채운다. |
| 순서기반교차 (order-basedcrossover) |
① 무작위로 위치를 선택한 후 해당 위치의 부모2 유전자 번호를 제외한 부모1의 유전자 번호와 위치를 자식에게 물려준다. ② 부모2의 유전자 번호 위치 순서에 맞춰서 자식 유전의 비어있는 위치에 제외한 유전자 번호를 채운다. |
| 위치기반교차 (position-basedcrossover) |
① 무작위로 위치를 선택한 후 해당 위치의 부모1 유전자 번호와 위치를 자식에게 물려준다. ② 부모2의 유전자 번호 위치 순서에 맞춰서 자식 유전자의 비어있는 위치에 제외한 유전자 번호를 채운다. |
-변이
변이는 부모의 유전자를 재조합해 자식 한 명을 생성하는 것으로 적합도를 높이는 교차와 달리 무작위 탐색에 가깝다. 따라서 돌연 변이를 일으켜 최적 해결책을 찾는 다는 효과가 있다.
변이의 종류론 치환, 역위, 전좌 등이 있다.
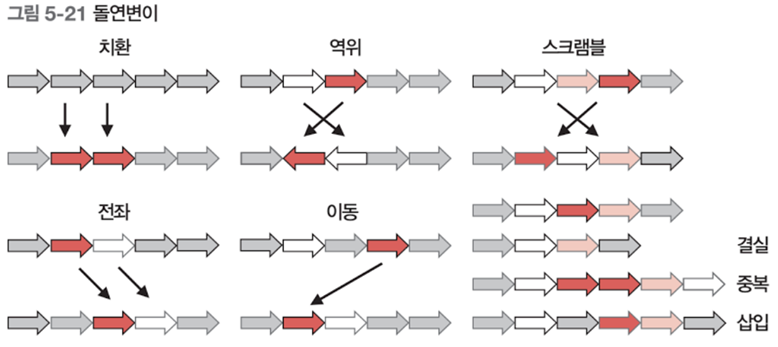
| 변이의 종류 | |
| 변이(돌연변이) | 설명 |
| 치환(Subsitiution) | 무작위로 선택된 유전자를 대립하는 유전자로 대체한다. |
| 섭동(Fluctuation) | (유전자가 실숫값인 경우) 무작위로 선택된 유전자에 매우 작은 양을 더하거 줄인다. |
| 교환(Exchange) | 무작위로 선택된 유전자 2개의 위치를 바꾼다. |
| 역위(Inversion) | 무작위로 선택된 유전자 2개 사이의 순서를 반대로 바꾼다. |
| 스크램블(Scramble) | 무작위로 선택된 유전자 2개 사이의 순서를 무작위로 바꾼다. |
| 전좌(Translocation) | 무작위로 선택된 유전자 2개 사이의 특정 유전자를 다른 위치로 바꾼다. |
| 이동(Shift) | 무작위로 선택된 유전자 2개 중 1개를 다른 유전자의 앞으로 이동시킨다. |
| 결실(Deletion) | 어떤 길이의 유전자를 제거(유전자 길이가 변화)한다. |
| 중복(Duplication) | 무작위로 선택된 유전자 2개를 복제(유전자 길이가 변화)한다. |
| 삽입(Insertion) | 어떤 길이의 유전자를 추가(유전자 길이가 변화)한다. |
4. 외판원 문제
유전 알고리즘의 사용 예로 대표적인 ‘외판원 문제’가 있다. 이 문제는 택배 회사 이외에도 실용적으로 널리 적용 될수 있다.
유전 알고리즘이 대표 적인 외판원 문제를 시뮬레이션 해본다.
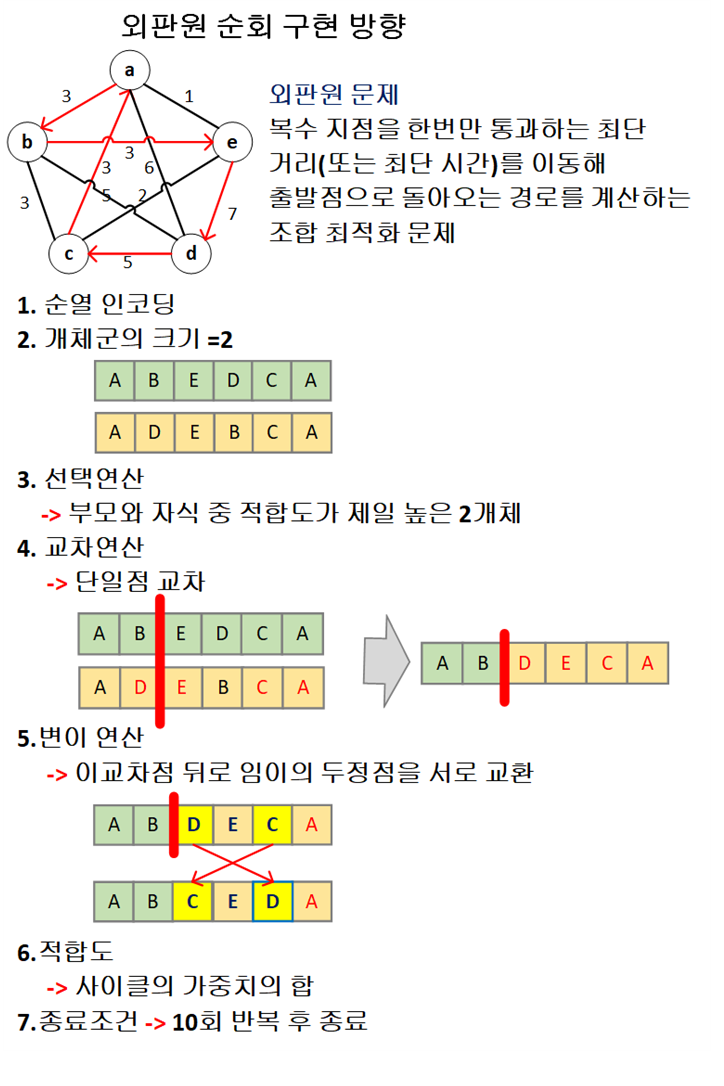
-시물레이션 결과
결과1
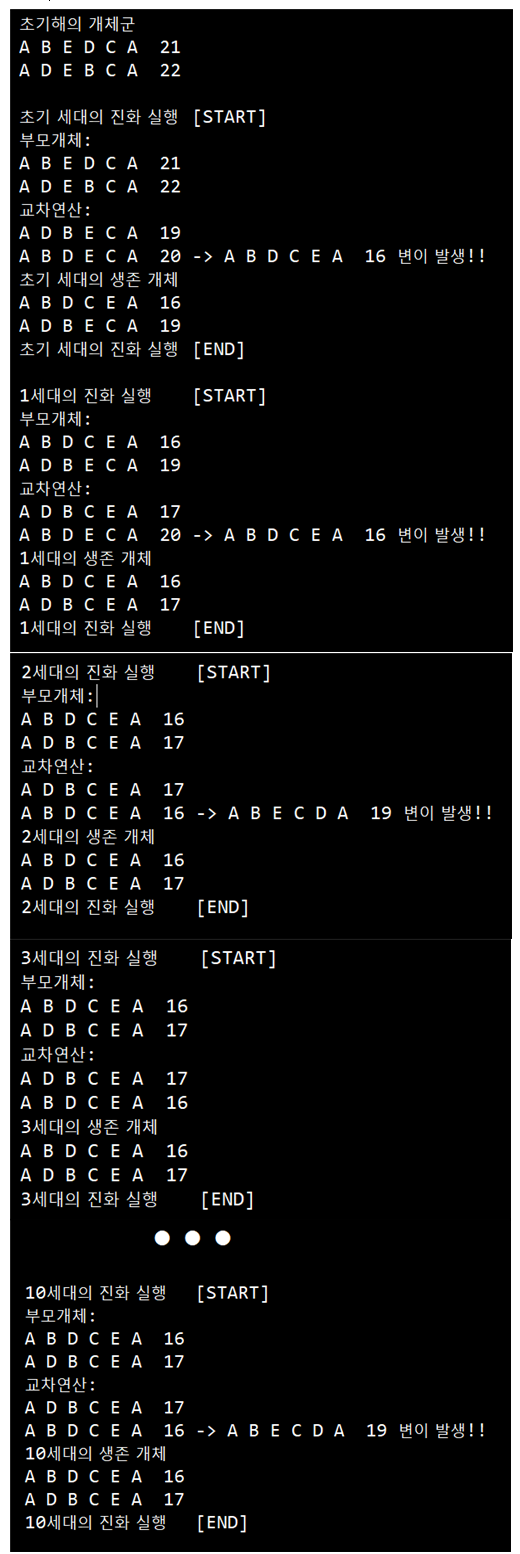
-시뮬레이션의 결론
교차점을 이용하여 특정 부모형질을 보존하고, 교차점 뒤의 유전형질을 돌연변이(변이)함으로써 부모형질을 물려받고 변이함으로써최적의 해를 구해 볼 수 있는데, 개체가 적어 부모의 개체와 자식 개체 중에 적합도가 높은 2개체를 선택 했던 것은 오류 였다. 부모와 자손 개체중 적합도가 높은 것을 고름으로써 특정 상황에서 교차가 무의미한 상황이 발생 하였다(개체가 적어 눈에 뛰는 결과가 나왔다).

부모와 자식 세대 중 A-D형질을 같는 개체만이 선택 됨으로써, A-B의 최초 부모 형질이 도태되었다.
최초 부모의 형질을 유지 하기 위해서 교차를 잘 활용하고, 돌연변이의 범주 설정이 적합도 만큼이나 중요한 과제이다.
- 구현 코드
아래와 같이 배열에 유전자 구조를 담는 형태를 사용하여,교차 및 변이를 만들어 주었다.
교차

변이
난수를 생성하여 확률이 높을 경우 변이를 일으키도록 하였다.

6. 결론
이번 프로젝트를 통해서 유전 알고리즘에 대해 알아보고, 구현해 봄으로써 유전 알고리즘을 이론적 고찰이 이루어 졌고 나름대로의 큰 성취가 있었다.
초기에는 유전 알고리즘에 있어서 풀고자하는 문제에 대하여 어떻게 유전적 형태를 만들 것인지와 적합도를 어떤식으로 구할 것인지가 제일 중요한 문제일 것이라고 막연히 생각을 했었다. 하지만 유전 알고리즘의 특징인 선택, 교차, 변이(돌연변이), 대치 등을 간과했었던 것은 문제였다. 교차를 통해서 부모형질을 물려받거나, 변이를 통해서 탐색의 범위를 확장 할 수 있고 단순히 세대를 거듭하여 좋은 해를 얻어 내는 게 아니라 적합도와 교차 변이의 밸런스를 통해서 보다 빠른 효율의 유전알고리즘을 구현 할수 있다는 것을 깨달았다.
참 고 문 헌
[1] 처음배우는 인공지능: 개발자를 위한 인공지능 알고리즘과 인프라 기초
[2] 쉽게 배우는 유전 알고리즘 -문병로
[3] 유전자 알고리즘의 수렴 속도 향상을 통한 효과적인 로봇 길 찾기 알고리즘
[4] 유전자 알고리즘을 이용한 확장성 있고 빠른 경로 재탐색 알고리즘
[5] 진화 시스템을 위한 유전 알고리즘 분석 및 개방형 REMAP architecture 구현
[6] 기타 Google.com / ko.wikipedia.org
'IT' 카테고리의 다른 글
| AI 발전 과정 개념 잡기 (3) | 2025.07.27 |
|---|---|
| [IT] Word2Vec 워드2벡터(단어를 벡터로 만들어 보자) (0) | 2024.06.08 |
| [IT]챗봇은 어떻게 확률을 이용해서 자연어를 만들어 낼까? (1) | 2024.06.08 |
| 개발자의 글쓰기 방법 (기술 블로거의 글쓰기 방법) (1) | 2024.04.11 |
| [IT용어]네이티브앱 vs 크로스 플랫폼 앱 (0) | 2022.11.07 |